Key findings
- Frontier AI models aren’t reliable on real bank statements. They look accurate on a clean page, but on the documents lenders actually receive they drop transactions, miscompute totals, and even report money coming in as money going out.
- Kita Max was the most accurate system tested — by a wide margin. It reported the correct figure 99.3% of the time, versus 67–84% for every frontier model and document-AI vendor in the benchmark.
- For lenders, that gap is the difference between a sound credit decision and a bad one. The balances and cash flows Kita reports reconcile to the statement, so you can underwrite on them with confidence.
Kita Capture is a document AI platform for lenders in emerging markets and underserved communities in the U.S. — places where a thin-file borrower’s bank statement is often the only credit history that exists. For these lenders, the useful question isn’t what the statement says line by line. It’s what the statement adds up to: the borrower’s average balance, their monthly inflow, their cash-buffer days. Those are the numbers an underwriting model runs on. So we built a benchmark that scores not just whether a system can read the page, but whether the numbers it calculates from the page can be trusted.
99.3%
Kita Max signal accuracy across 62 statements. Standard Kita: 97.6%.
67–84%
Signal accuracy range for every other system. Even the best gets roughly one in six of its reported totals wrong.
28 vs 0
The other systems got 28 cash flows backwards — money in shown as money out. Kita Max got 0 wrong.
The result was sharper than we expected. On a clean page the frontier models look almost interchangeable — barely two points separate them on raw field accuracy. But reading every line correctly is not the same as getting the totals right: on dense statements the same models leave out transactions, and the figures they report come back wrong, sometimes by orders of magnitude. Only the Kita systems stayed accurate from the raw rows through to the final numbers. This post walks through the corpus, the methodology, the leaderboard, and the real failure cases.
The corpus: 62 real bank statements from 4 emerging markets
62 real, de-identified consumer and SME bank and e-wallet statements, chosen to look like a production lending pipeline rather than a clean academic set: phone screenshots, scanned PDFs, multi-account statements, multilingual layouts, and European-style number formatting.
62 statements · 4 countries · ~2,200 transactions
Philippines
BDO · BPI · GoTyme · Maya · GCash · SeaBank · Metrobank — including e-wallets and phone screenshots
Indonesia
BCA · BRI · BNI · Permata · Danamon — Bahasa-language layouts, dense multi-page registers
Mexico
BBVA · Banorte · Banamex · HSBC — dense multi-page CFDI statements with CLABE / RFC fields
United States
Chase · TD · Truist · US Bank · First Citizens — the clean baseline
The systems we tested: 9 extraction pipelines
Every system gets the identical schema, document, and grader. Kita appears in two configurations — Kita, the production pipeline, and Kita Max, our highest-accuracy tier.
Kita Max ★
Highest-accuracy tier
Kita ★
Production pipeline
Claude Sonnet 4.6
GPT-5.5 (low)
Gemini 3 Flash
Gemini 2.5 Flash
Reducto Extract
Landing AI ADE
LlamaExtract
Methodology: how we scored bank-statement extraction
Every output is scored against a real answer key. PhD-level financial analysts hand-curated the correct schema and the ground-truth value of every field, and every output was graded by hand against that key. Nine systems, the same schema, the same documents, the same human graders.
- 1
Curate ground truth
PhD-level financial analysts read every statement and hand-curate the correct schema and the true value of every field.
- 2
Extract
All nine systems fill the identical schema on the same document. No tools, no hints. Invented fields are dropped; missing ones are null.
- 3
Hand-grade
Human graders score every field of every output against the answer key. No model grades another model.
- 4
Check the math
Every reported total, average, and balance is checked against the actual figure on the statement.
Results: reading accuracy vs. signal accuracy
We start with the thing a lender actually decides on: the signals. Even when a system reads every transaction correctly, the totals it reports can still be wrong — total credits, total debits, average balance, and net cash flow coming back different from the actual figures on the statement. So every reported aggregate is checked against the true value, on every document. This is where the field falls apart.
- 1Kita Max ★99.3%
- 2Kita ★97.6%
- 3GPT-5.5 (low)83.5%
- 4Gemini 3 Flash78.6%
- 5Claude Sonnet 4.677%
- 6Gemini 2.5 Flash72.9%
- 7Reducto Extract70.2%
- 8LlamaExtract67.8%
- 9Landing AI ADE67.3%
Kita Max’s reported figures are right 99.3% of the time, and Kita’s 97.6%. The best LLM manages 83.5%; the parse-and-extract vendors fall to the high-60s. They read the statement, then report totals it doesn’t support.
What about raw reading? On field extraction the nine systems land within two points of each other, with Kita Max effectively tied for the top score. But this is the metric that flatters the frontier models most: it rewards transcribing a clean page and says nothing about whether the result is complete or the arithmetic holds up — and on dense statements, as we’ll see, the same models fall apart.
- 1GPT-5.5 (low)98.7%
- 2Kita Max ★98.6%
- 3Claude Sonnet 4.698.5%
- 4Kita ★98.2%
- 5Gemini 3 Flash98%
- 6Reducto Extract97.6%
- 7Landing AI ADE97.3%
- 8Gemini 2.5 Flash97.1%
- 9LlamaExtract96.9%
The nine systems land within two points of each other — raw reading is effectively a tie. The gap that matters opens up only when the reported totals are checked.
A model that reads perfectly but can’t be trusted to total a column is not a lending pipeline; it’s a very good transcriber. Kita Max gives up a tenth of a point of reading to the best frontier model and returns fifteen points of signal accuracy. That is the trade a lender wants.
One statement, nine answers: the average-balance test
The clearest way to see the problem is to take a single document and ask every system for one number a lender cares about: the average end-of-day balance. Here is a real bank statement (Security Bank) — 33 transactions, with a running-balance column printed on every row, so there is exactly one correct answer: ₱5,845.64.
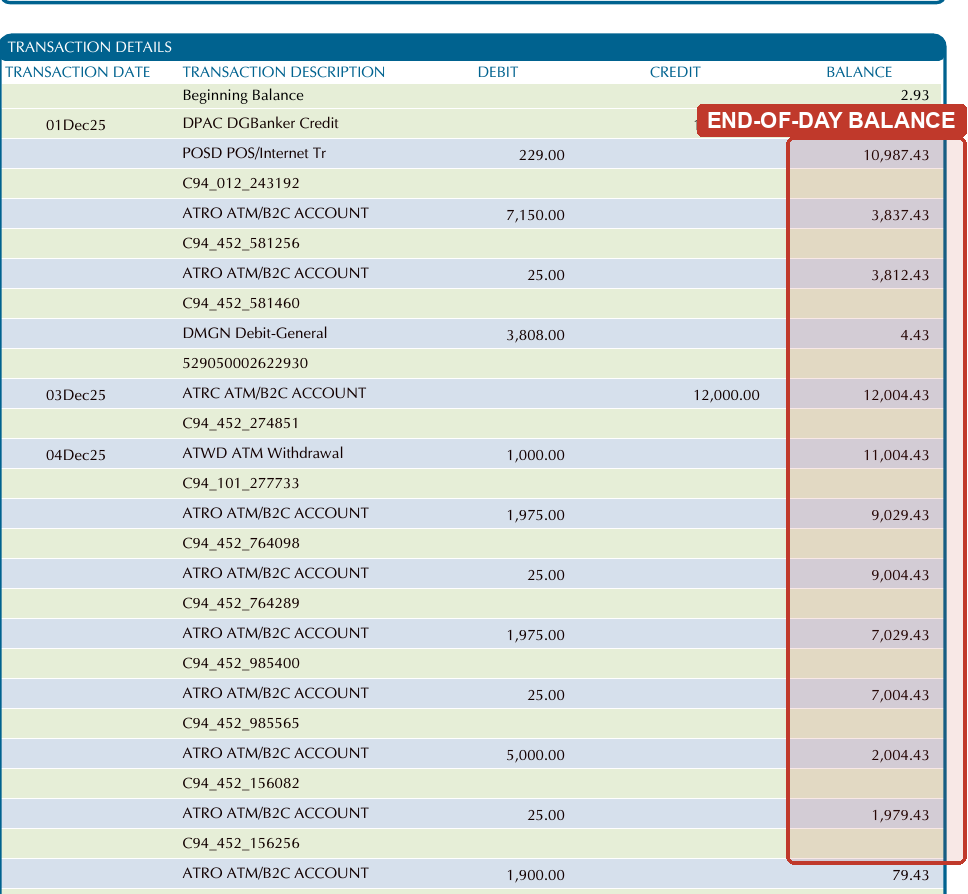
Reported average end-of-day balance
Correct answer: ₱5,845.64
- Kita Max₱5,845.64
- Kita₱5,845.64
- Landing AI ADE₱5,900
- Claude Sonnet 4.6₱3,671.70
- GPT-5.5 (low)₱2,982.50
- Gemini 3 Flash₱1,127.81
- LlamaExtract₱5.00
Every system read the transactions correctly. Asked for the average of a column printed on the page, they returned answers spanning ₱5 to ₱5,900. Landing AI lands within 1% but is still off; the Kita systems compute the average in code from the extracted rows, so the reported figure matches the statement. Depending on the vendor, a lender pulling the “average balance” field would see this borrower as nearly broke or comfortably liquid — from the same statement.
Right rows, wrong totals
The Security Bank case isn’t a one-off. Every system does two separate things: it reads the list of transactions, and it reports the aggregate signals — total inflow, average balance — alongside them. Even when the reading is perfect, the reported totals routinely aren’t. Here is a February bank statement from BPI: the total inflow each system reported, next to the actual figure.
| System | Reported | Actual | Discrepancy |
|---|---|---|---|
| Kita Max | ₱3.21M | ₱3.21M | exact match |
| Kita | ₱3.21M | ₱3.21M | exact match |
| GPT-5.5 (low) | ₱2.88M | ₱3.21M | ₱330k low |
| Reducto Extract | ₱2.53M | ₱3.21M | ₱0.68M short |
| Landing AI ADE | ₱67.1M | ₱3.21M | 21× too high |
Several of these systems read every transaction on this statement correctly, and the total they reported is still wrong — Landing AI 21× too high, Reducto ₱0.68M short, GPT-5.5 missing a ₱330k deposit. None of them is missing the data; they all read the deposits on the page. For a lender, the reported total is the input to the credit model, and three of these five feed it a number the statement doesn’t support.
Where everyone struggles: dense, multi-page statements
The hardest documents are dense Mexican multi-account statements. This BBVA statement runs 14 pages and about 209 transactions, and completeness fractured badly. The dangerous part: every system returned perfectly well-formed JSON. It just contained half, or a seventh, of the borrower’s actual activity.

Transactions extracted (true ≈ 209)
Silent under-extraction is the most dangerous failure mode in lending.
- Kita Max209 rows
- Kita209 rows
- Claude / Gemini 3 / Reducto209 rows
- GPT-5.5 (low)111 rows
- Gemini 2.5 Flash49 rows
- LlamaExtract29 rows
LlamaExtract dropped 86% of the borrower’s transactions and reported a tidy schema anyway. Every signal computed from those 29 rows is then confidently wrong. Kita and Kita Max captured all ~209.
When a deposit reads as a withdrawal
Reading a number correctly is only half of a transaction; the other half is its direction — money in or money out. Net cash flow, the single clearest measure of whether a borrower is accumulating or depleting, depends on classifying every row as a debit or a credit and then summing with the right sign. Systems got the amounts right and the direction wrong often enough to flip the answer outright:
| System | Statement | Reported | Actual |
|---|---|---|---|
| Kita Max | BDO, Philippines | −₱46,801 | −₱46,801 |
| Kita | BDO, Philippines | −₱46,801 | −₱46,801 |
| Claude Sonnet 4.6 | BDO, Philippines | +₱14 | −₱46,801 |
| Gemini 2.5 Flash | BPI · May | −₱1.42M | +₱23.1M |
| Reducto Extract | BPI · February | +₱331,721 | −₱8.77M |
| GPT-5.5 (low) | BBVA, Mexico | +9,021 | −181,039 |
Across the corpus, 28 net-cash-flow figures came back with the wrong sign. A sign flip turns a saver into a spender: to an underwriting model, a borrower with a healthy positive surplus instead reads as one bleeding cash — or the reverse, which is worse. Because the Kita systems classify debit-vs-credit deterministically from the statement’s columns rather than re-deciding it mid-computation, Kita got the direction wrong on just one statement in the 62-document corpus, and Kita Max on none.
Where Kita still has work to do
We hold ourselves to the same scrutiny. Kita’s lowest-scoring documents come from over-extraction, not the under-extraction that sinks others. On this SeaBank statement it pulled rows out of an “Interest & Tax Detail” sub-table and treated them as transactions. It’s the right kind of problem — extra signal to suppress rather than missing signal to invent — and the benchmark is doing its job by surfacing it. Kita Max’s table classifier already suppresses this sub-table correctly; that fix is now rolling into the production pipeline.
True = 33. Kita’s miss is over-extraction — it pulled in rows from an interest sub-table — not the under-extraction that sinks other systems.
- Kita52 rows (+19 interest)
- Kita Max33 rows
- Most systems33 rows
Why this matters for lenders
If you only benchmark whether a system reads a page, every modern model looks like a solved problem — they’re all 97%+. But “read the page” is not the job. For a lender, the job is asking: what is this borrower’s average balance, their net monthly cash flow, their minimum buffer? To produce those, a system has to read every transaction and do the arithmetic correctly and not contradict itself.
That last step is where the field falls apart. The frontier LLMs are extraordinary transcribers and unreliable accountants. The parse-and-extract vendors are strong on clean docs and dangerously inconsistent on dense ones. Across 62 statements and ~2,200 transactions, only the Kita systems reported totals that hold up against the statement more than 84% of the time — because the arithmetic is never delegated to a language model. Average end-of-day balance, net cash flow, buffer days, recurring income — the features underwriting actually runs on — are computed in code from the extracted rows, so they hold up.
Don’t trust a credit signal you can’t reconcile to a row. Benchmark the math, not just the reading.
See Kita on your own bank statements
The signals a lender underwrites on — average balance, net cash flow, buffer days, recurring income — are only as trustworthy as the arithmetic behind them. Kita Capture extracts every transaction and computes those signals in code, so the numbers reconcile to the statement. Run it on a sample of your own borrower files and check the totals yourself.
Want to see how Kita performs on your own documents?
Book a demoFrequently asked questions
What is the most accurate bank statement extraction tool in 2026?
In this 62-statement benchmark, Kita Max was the most accurate, with 99.3% signal accuracy — the share of reported totals that match the statement. Standard Kita scored 97.6%. The best general-purpose LLM, GPT-5.5, reached 83.5%, and the parse-and-extract vendors (Reducto, LlamaExtract, Landing AI) fell to the high 60s.
How accurate are LLMs like GPT-5.5, Claude, and Gemini at reading bank statements?
They read individual transactions well. On field-by-field extraction the nine systems scored within about two points of each other (96.9%–98.7%), so raw reading is largely a solved problem. The difference shows up in what they do with that reading: on long, multi-page statements some models return only part of the transactions, and the totals they calculate — balances, inflows, cash flow — are correct less often. Measured on those calculated figures, which are what lenders underwrite on, Kita Max was the most accurate system in the benchmark at 99.3%, compared with 67–84% for the frontier LLMs and document-extraction vendors.
Why do AI models get bank statement totals wrong?
Because they generate aggregates — total inflow, average balance, net cash flow — as text rather than computing them in code from the extracted rows. A model can transcribe all 209 rows of a statement correctly and still report a total that is 21× too high or short by hundreds of thousands.
What is signal accuracy, and why does it matter for lending?
Signal accuracy measures whether the figures a system reports — average balance, total inflow, net cash flow, buffer days — match the actual values on the statement. Those derived signals are the inputs to an underwriting model, so an unreliable signal produces an unreliable credit decision, even when every transaction was read correctly.
Can AI reliably extract every transaction from a long bank statement?
Not always. The most common failure is silent under-extraction: a system returns clean, well-formed output that contains only part of the statement. On one 209-transaction Mexican statement, a tool returned just 29 rows — dropping 86% of the activity — with no error, so every figure calculated from it was wrong.
How large was the benchmark and how was it graded?
62 real, de-identified bank and e-wallet statements — roughly 2,200 transactions — from the Philippines, Indonesia, Mexico, and the United States. PhD-level financial analysts hand-curated the ground truth, and all 558 outputs were graded field by field by humans, with no LLM acting as judge.
How does Kita reach higher signal accuracy than frontier LLMs?
Kita extracts the transaction rows, then computes every aggregate — average balance, net cash flow, recurring income — in code from those rows, and classifies each row as debit or credit deterministically from the statement’s columns. The arithmetic is never delegated to a language model, so the reported figures reconcile to the statement.
Related reading
Kita · Benchmark report · June 2026